
Arista: A Second-Order Winner From Disaggregated Inference
As AI inference becomes a distributed systems problem, open Ethernet fabrics and network automation become more important to cost-per-token optimization

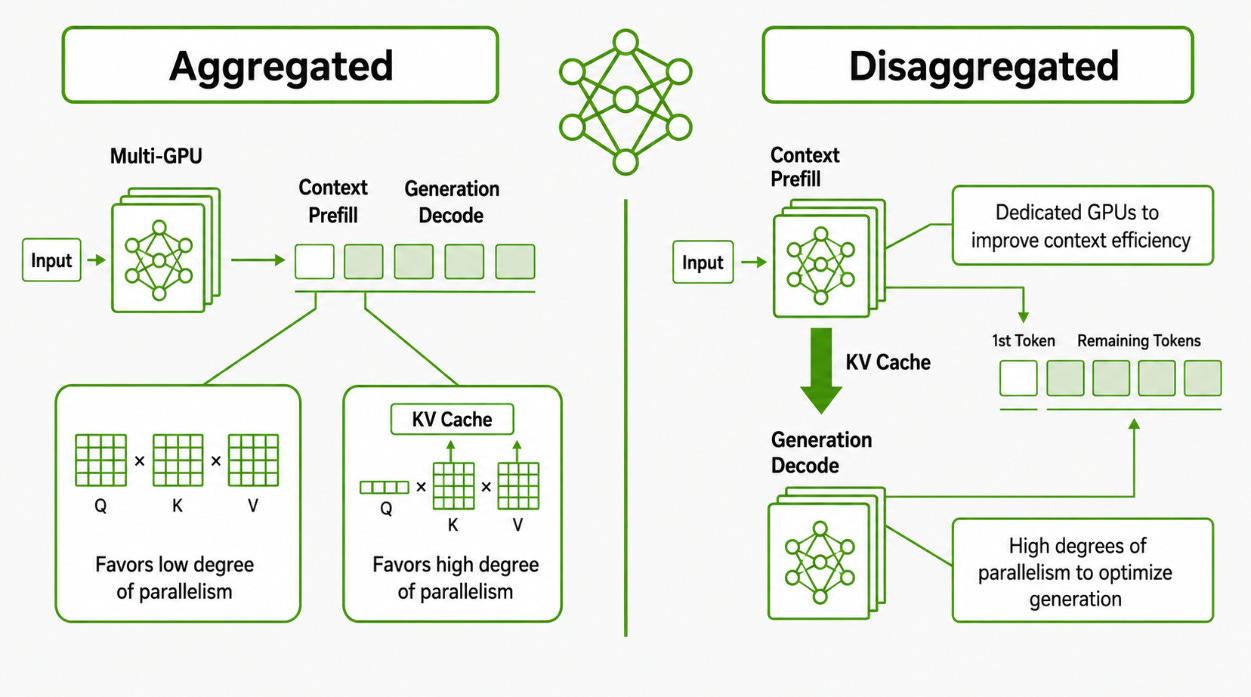
Inference performance is increasingly determined by the system around the model: routing, scheduling, KV-cache movement, quantization, multi-token prediction, and the ability of clusters to handle bursty east-west traffic.
That shift increases the strategic value of the network layer. Large inference clusters require high-density 400G/800G Ethernet fabrics, low-latency switching, deep buffers, VOQ, adaptive routing, congestion management, and automation that can support constant configuration, validation, and tuning. This is where Arista becomes one of the second-order beneficiaries
Disaggregated inference accelerates the network’s importance
The Baseten GLM-5.2 result is a good example of where the market is moving. The 280+ tokens/sec output came from the serving system around the model: quantization, KV-aware routing, disaggregated inference, multi-token prediction, and NVIDIA Dynamo tooling. NVIDIA remains central, but more of the incremental performance gain is coming from the broader inference architecture.

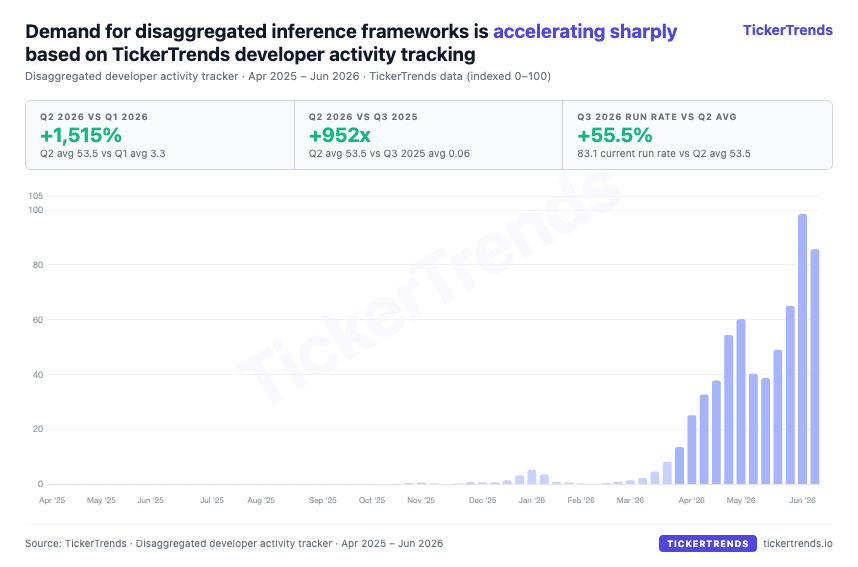
TickerTrends data shows the same shift. Disaggregated inference developer activity increased 1,515% in Q2 2026 versus Q1, with the Q3 run rate already 55.5% above the Q2 average. This reflects the industry separating prefill from decode, moving KV caches across GPU pools, and optimizing routing and scheduling for long-context and reasoning workloads.
As workloads are split across resources, inference becomes more of a networking problem. Large KV transfers, RDMA/RoCE efficiency, incast, congestion, multi-tenant isolation, and cluster-wide scheduling all become more important. Arista’s advantage is that it gives customers a cost-efficient, flexible Ethernet fabric for these AI clusters while preserving openness and avoiding dependence on a single integrated infrastructure stack.
TickerTrends Arista signals also point to demand pull-through
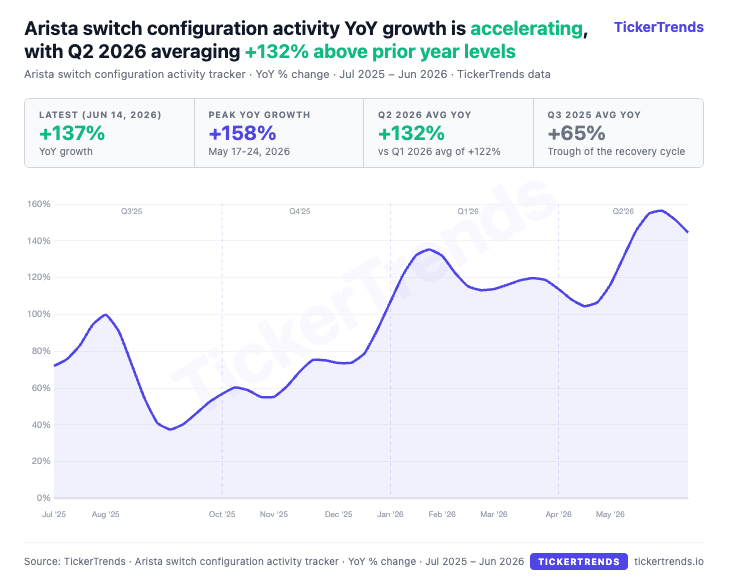
Arista switch configuration activity is up 137% YoY, with Q2 averaging +132% YoY. Large AI fabrics require more configuration, validation, and tuning, which makes this a useful proxy for deployment intensity.
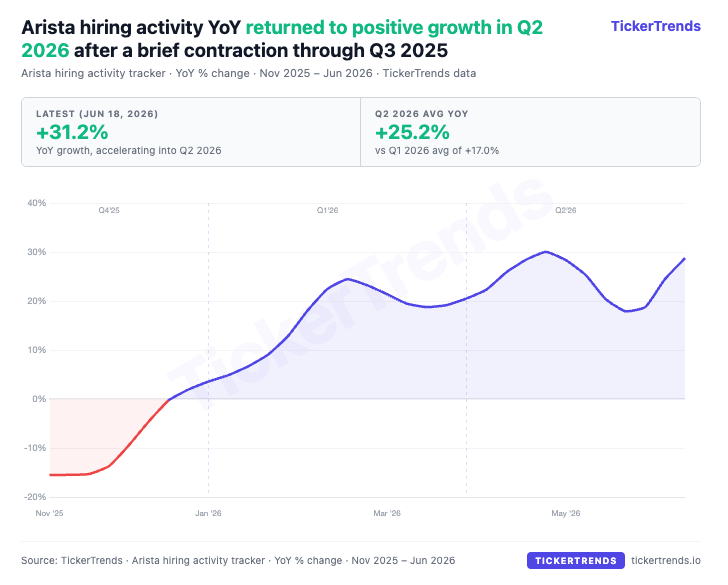
Hiring: returned to positive growth, latest reading +31.2% YoY, Q2 averaging +25.2% YoY, consistent with demand pull-through as AI networking takes a larger share of datacenter spend.
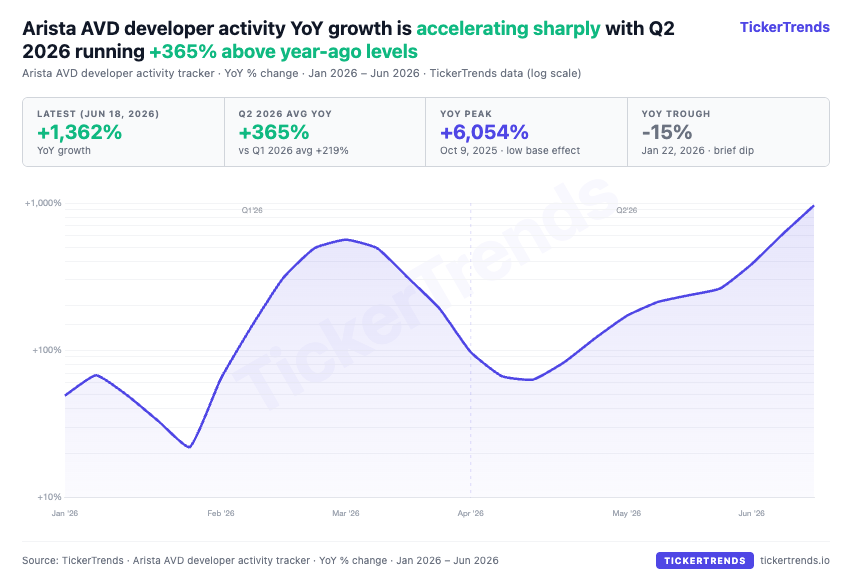
AVD developer activity, Arista’s automation ecosystem, is up 1,362% YoY, with Q2 running 365% above year-ago levels. Elevated AVD usage points to deeper engagement with open Ethernet builds and more operational complexity inside large AI fabrics.
Risks and counterpoints
The main risk is that NVIDIA Spectrum-X continues to win deployments where customers prioritize speed, integration, and a single-vendor path. Cisco, Broadcom-powered platforms, and whitebox Ethernet also create pricing pressure. Memory inflation is another near-term margin risk if higher component costs cannot be fully passed through.
But the broader direction is still favorable for Arista. As inference scales, customers are likely to care more about performance per dollar, operational flexibility, and avoiding overly closed infrastructure stacks. Higher memory and accelerator costs may actually increase the importance of cluster utilization, because idle GPUs and inefficient KV-cache movement become more expensive.
Conclusion
Arista is not the only beneficiary of disaggregated inference. NVIDIA and Broadcom are more direct beneficiaries at the stack and silicon layers. The Arista thesis is more specific: as inference becomes a distributed systems problem, customers that want open, lower-cost Ethernet fabrics should increase spend on switching, automation, and configuration-heavy AI networks. The TickerTrends signals suggest that this second-order pull-through is already showing up.